NGS Quality Filtering
Introduction Notes¶
Challenges¶
We are going to do the quality control and then filter the fastq files accordingly. Please work in groups and choose one of the datasets. When you are finished, you can use the next. Post your comments, commands and questions directly in the Google group.
Login to our server.
ssh studentX@gdcsrv2.ethz.ch
Let's generate a new working folder, open it, download the data and open the tar file.
mkdir QF cd QF wget https://www.gdc-docs.ethz.ch/GeneticDiversityAnalysis/GDA20/data/QF.tar.gz tar xvzf QF.tar.gz ls
Additional Information to the fastq datasets:
A: example_A.fq.gz: RNAseq data, HiSeq4000
B: example_B.fq.gz: DNAseq, HiSeq4000
C: example_C.fq.gz: ddRAD data, HiSeq2500
D: example_D.fq.gz: Amplicon Sequencing, MiSeq
E: example_E.fq.gz: Amplicon Sequencing, HiSeq2000
F: example_F.fq.gz: DNAseq data, HiSeq2000
G: example_G.fq.gz: DNAseq data, unknown
H: example_H.fq.gz: Metagenomics, Hiseq2500
I: example_I.fq.gz: DNAseq (10X), NovaSeq
J: example_J.fq.gz: DNAseq, reverse reads, NovaSeq
Quality control¶
For the quality control we will use
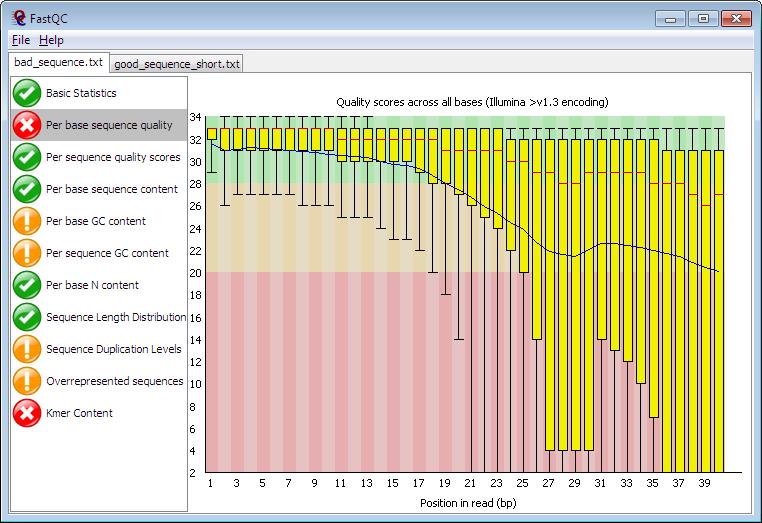
Fastqc will provide you the famous read statistics whereas fastq screen aligns a subset of the sequences against some standard databases (e.g. ribosomal RNA, adapters, Human) to get quickly an idea what you have sequenced. Many sequencing facilities might provide you both outputs, therefore, it is importand to have a closer look at them.
With the following command you can run fastqc and a html file will be generated.
fastqc example_A.fq.gz
We have provided the fastq screen outputs already (example_A_screen.html). You can copy (cyberduck) the html files to your computer and open them in your browser.
What do you think about the sample? Is there a problem?
Quality filtering¶
Depending on the problem that you have found in your dataset you can filter the reads using BBDuk of the bbmap package. Below you find some important commands. If you need more information about bbduk just type bbduk.sh -h.
Find a list of all Illumina adapters here.
(1) With the following command you remove bases with quality below Q15 from both sides and retain only reads that are longer than 100 bp.
bbduk.sh -in=example_fq.gz -out=example_trim.fq.gz qtrim=rl trimq=15 minlength=100
And/or you can for example remove adapters (AGAGCACACGTCTGAACTCCAGTCACTGACCAATC) as following.
bbduk.sh -in=example_fq.gz -out=example_trim.fq.gz literal=AGAGCACACGTCTGAACTCCAGTCACTGACCAATC
If you expect only partial hits with the adapter (is most often the case) you can set a certain kmer length (the adapter needs to fit only partially).
bbduk.sh -in=example_fq.gz -out=example_trim.fq.gz literal=AGAGCACACGTCTGAACTCCAGTCACTGACCAATC ktrim=r k=23 mink=11
With the follwoing command you remove partial hits with adapters, trim low quality bases and keep only sequences > 100 bp.
bbduk.sh -in=example_fq.gz -out=example_trim.fq.gz literal=AGAGCACACGTCTGAACTCCAGTCACTGACCAATC ktrim=r k=23 mink=11 qtrim=rl trimq=15 minlength=100
(2) Now you can rerun fastqc to verify if you could filter your reads.
(3) For other tools there is no need to specify if you like to remove adapters or do a quality trimming, everything will be performed in one goal. Fastp is still under development but has many powerful options and is really fast.
fastp -i exampleA_fq.gz -o exampleA_trim.fq.gz
Some suggestions can be found here.